
Requisitos mínimos para execução do tutorial:
- Uma conta na magalu cloud com public preview habilitado
- Conhecimento em linux
- Conhecimento em docker containers
- Conhecimento em Github
- Um computador, claro, executando qualquer sistema operacional com acesso a internet
Como Product manager dos produtos de object storage e block storage na magalu cloud, tenho orgulho de estar participando da construção da primeira cloud brasileira. Com documentação e suporte em português, regiões no Brasil enfim, uma cloud pra chamarmos de nossa!
Recentemente iniciamos nosso public preview onde, disponibilizamos ao mercado Virtual Machines e Block Storage além de já termos lançado Object Storage no início de abril então, pensei, porque não construir uma solução bacana de IA usando essas 3 ferramentas ? Pois bem, vamos lá!!!
O que é RAG?
Dentro do universo NLP ( Natural Processing Language), o advento das LLMs ( Large Language Models ) foi e vem sendo uma revolução no mundo moderno e nesse ambiente o RAG ( Retrieval-Augmented Generation – Geração de Retorno aumentado ) tem seu destaque.
RAG, basicamente é uma técnica que combina a busca por informações em fontes externas ( retrieval ) com a geração de texto feita por modelos de IA, como o GPT, para criar respostas mais precisas e contextualizadas. Em outras palavras imagine você ter um modelo, como o chat-GPT, contextualizado em um determinado assunto podendo orientá-lo a se basear naquele contexto e ser um “especialista” em determinado assunto. Pois bem, essa técnica é chamada RAG.
Estudo de caso de IA – na Magalu Cloud
Trocando uma idéia com nosso saudoso Leonardo Claudio de Paula e Silva ( Chapter Lead – Machine Learning ) aqui da Luiza Labs obtive uma recomendação excelente: A ferramenta open-source dify. Basicamente é uma ferramenta pra desenvimento de LLMs, orquestração de aplicações de workflows de agentes de IA usando um motor RAG. E tudo isso com uma interface limpa, moderna e uma usabilidade fluída!
A ferramenta oferece, mesmo sendo open source, uma gama de preços ( para hospedagem com eles ) e um sandbox que é free para 200 mensagens. Isso quer dizer, mensagens para os modelos disponíveis que, aliás, temos vários já configurados como Anthropic, Llama2, Azure OPenAI, Hugging Face, etc.
Como nosso intuíto é fazer isso na MGC ( Magalu Cloud ) vamos configurar essa ferramenta dentro da estrutura da cloud e assim, não teremos essa limitação! Bora lá?
A implementação
- Inicialmente, acesse a magalu.cloud e crie uma conta. Também habilite o Public Preview para ter acesso aos produtos de Virtual Machine e Block Storage.
- Após ter criado sua conta acesse o Portal da cloud. Você verá uma tela como essa:
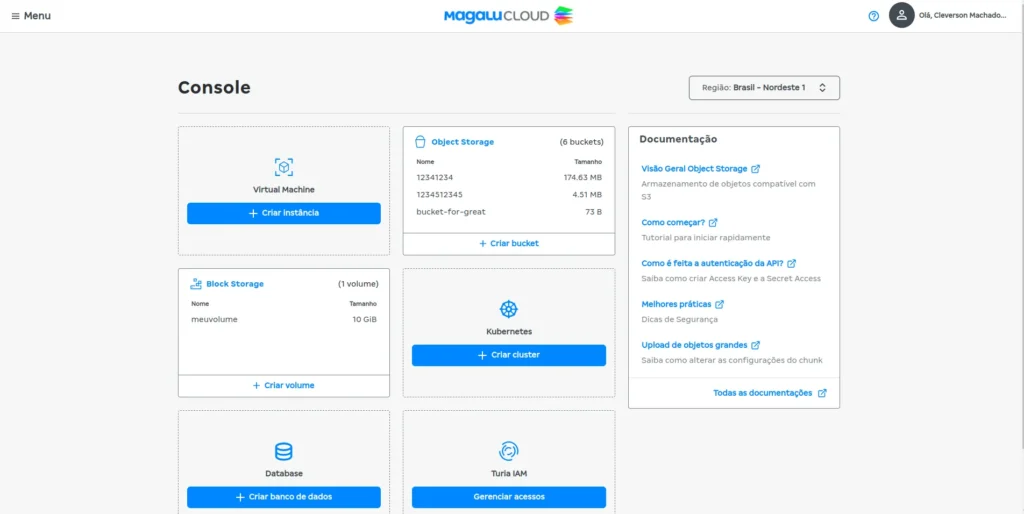
Após ter entrado no portal, na sessão Virtual Machines clique em:

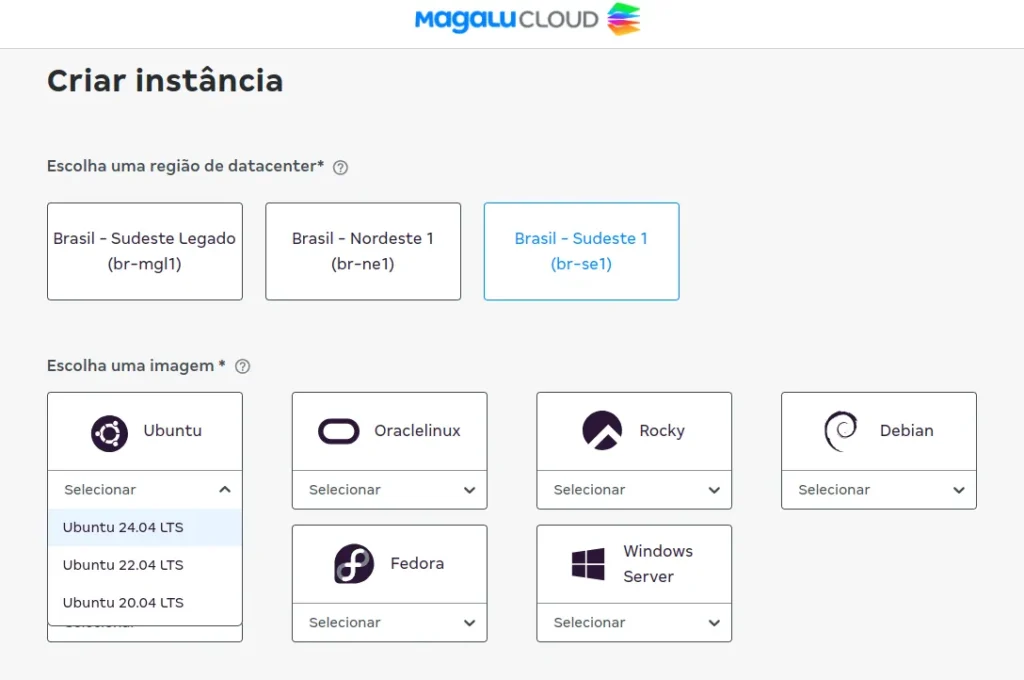
- Na tela de criação de instância selecione a região ( br-se1 – Sudeste ) e a imagem para sua VM. No meu caso eu selecionei o ubuntu 24.04 LTS.
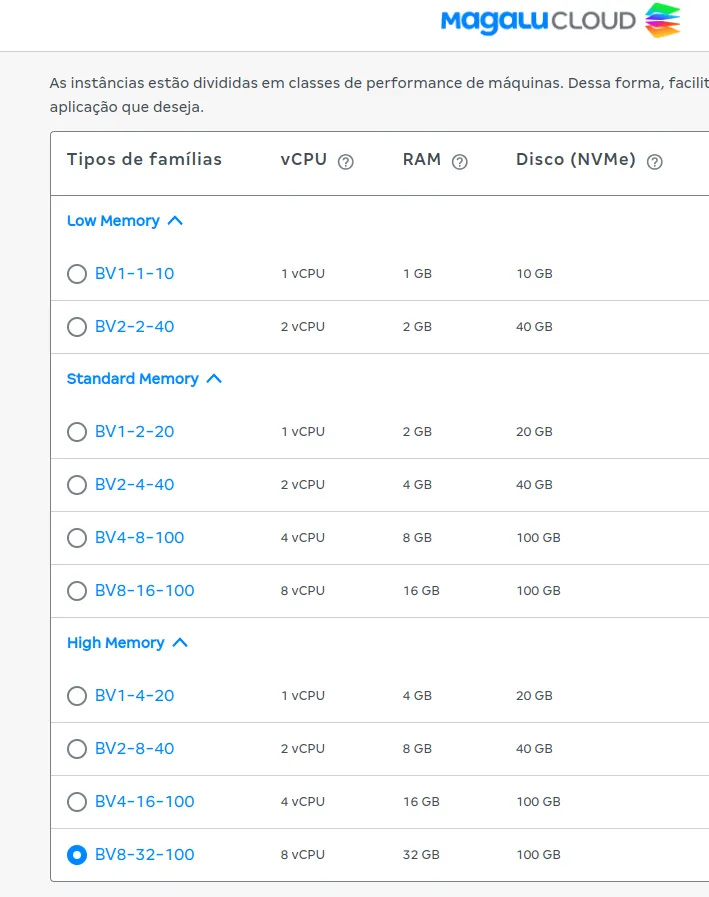
- Após isso, selecione o tipo de instância ( a instância recomendada para esse caso de acordo com o próprio dify seria ≥ 2 CPUs e RAM ≥ 4 GB.
Para acesso a máquina devemos criar ou inserir uma chave ssh existente. No meu caso, como estou utilizando, na minha máquina local, o sistema operacional ubuntu é só executar o seguinte comando no prompt do terminal:
ssh-keygen -t rsa- Após isso, seguir os passos correspondentes e voalá. Só nomear a sua chave e colocar o hash da chave pública no espaço devido. É importante dizer que a chave não deverá ter quebras de linha. Para maiores informações sobre o procedimento de criação de chave ssh consulte.
- Nomear a instância
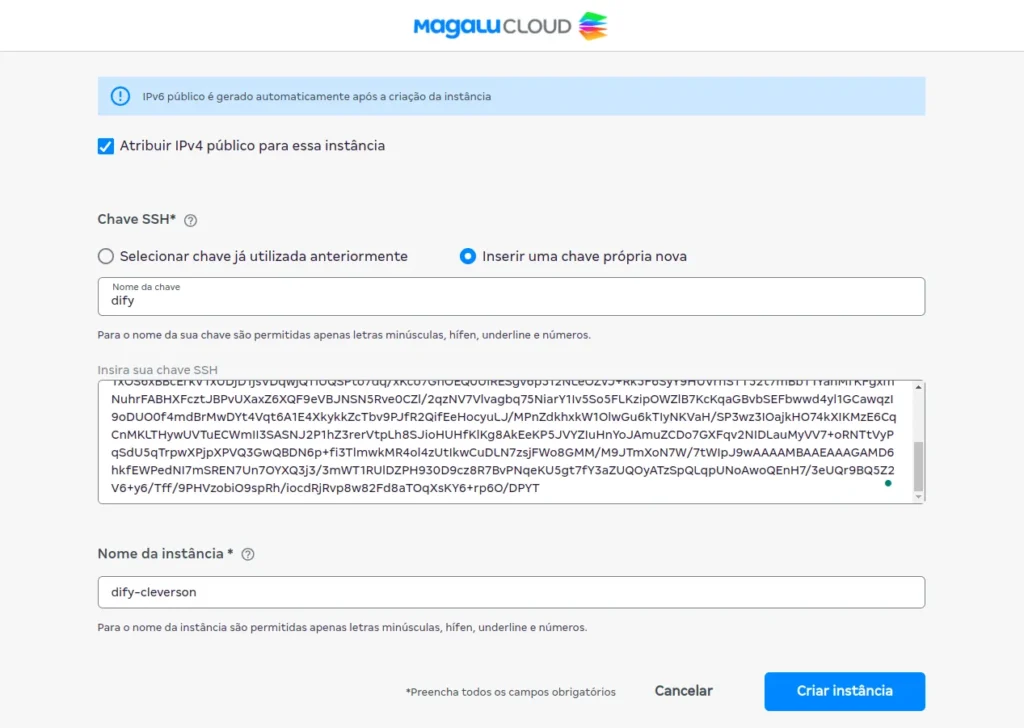
- Clicar em criar instância
- Após sua instância criada é hora de acessá-la. Pegue o IPv4 Público disponível clicando na sua VM e depois em copiar como abaixo:
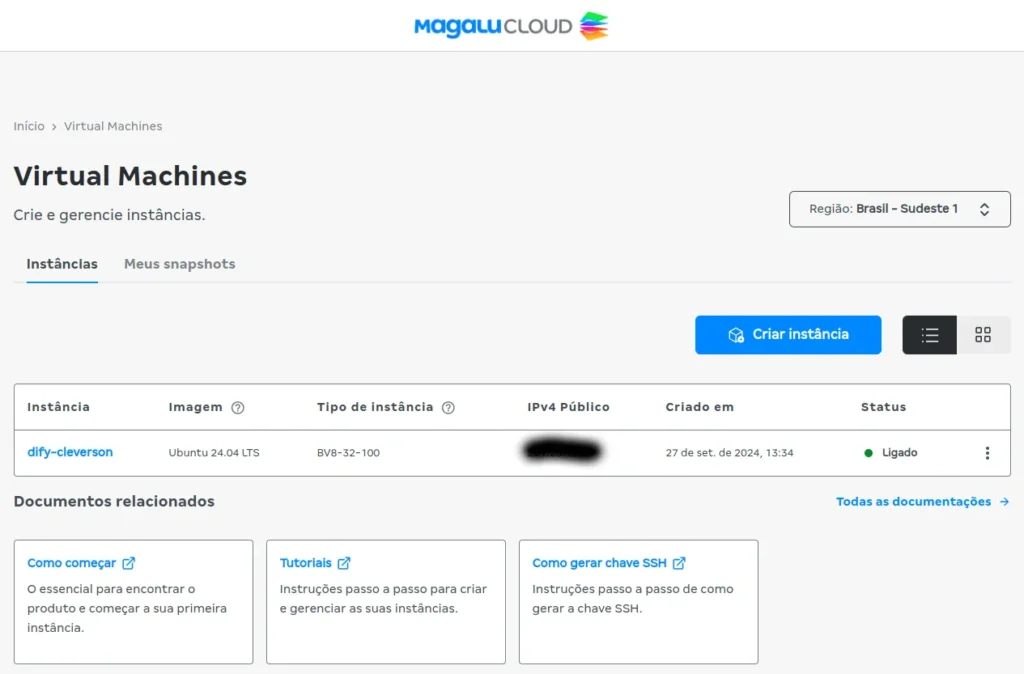
- Após pegar o ip público de sua VM é só conectar via terminal usando ssh. No meu caso, no ubuntu, utilizei o comando abaixo:
ssh ubuntu@o_ip_da_sua_vmA partir da conexão com a máquina a idéia é executar os comandos conforme o manual.
- instalar o docker na sua máquina, no meu caso ubuntu, seguindo o tutorial.
- Clonar o repositório na sua VM
git clone https://github.com/langgenius/dify.git- Navegar até o diretório docker
cd dify/docker- Copiar o arquivo de configuração de ambiente
cp .env.example .env- configurar o MGC Object Storage como repositório principal da ferramenta. No console da MGC clique em:

- Clique em API Keys para abrir a sessão de APIs
- Clique em
- Com o ID e secret em mãos é hora de configurar o arquivo .env do docker. Configure o arquivo conforme o secret e ids criados.
nano .env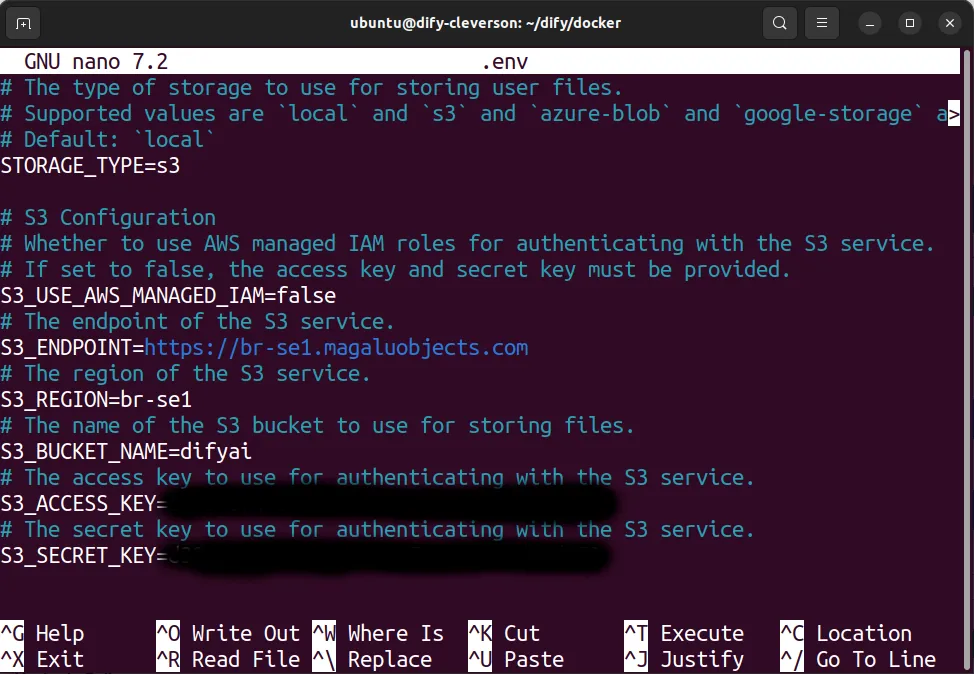
- Após salvo o arquivo vamos subir o docker containers
docker compose up -d- Depois de executar o comando você deve ver uma saída similar a essa
[+] Running 11/11
✔ Network docker_ssrf_proxy_network Created 0.1s
✔ Network docker_default Created 0.0s
✔ Container docker-redis-1 Started 2.4s
✔ Container docker-ssrf_proxy-1 Started 2.8s
✔ Container docker-sandbox-1 Started 2.7s
✔ Container docker-web-1 Started 2.7s
✔ Container docker-weaviate-1 Started 2.4s
✔ Container docker-db-1 Started 2.7s
✔ Container docker-api-1 Started 6.5s
✔ Container docker-worker-1 Started 6.4s
✔ Container docker-nginx-1 Started 7.1sVerificar se containers estão funcionando:
docker ps -aA saída deverá ser algo parecido com a abaixo:
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:0.6.13 "/bin/bash /entrypoi…" api About a minute ago Up About a minute 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db About a minute ago Up About a minute (healthy) 5432/tcp
docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx About a minute ago Up About a minute 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis About a minute ago Up About a minute (healthy) 6379/tcp
docker-sandbox-1 langgenius/dify-sandbox:0.2.1 "/main" sandbox About a minute ago Up About a minute
docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy About a minute ago Up About a minute 3128/tcp
docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate About a minute ago Up About a minute
docker-web-1 langgenius/dify-web:0.6.13 "/bin/sh ./entrypoin…" web About a minute ago Up About a minute 3000/tcp
docker-worker-1 langgenius/dify-api:0.6.13 "/bin/bash /entrypoi…" worker About a minute ago Up About a minute 5001/tcpA interface dify
- Após o sucesso de “deployar” o dify você poderá fazer o acesso via browser
http://seu_ip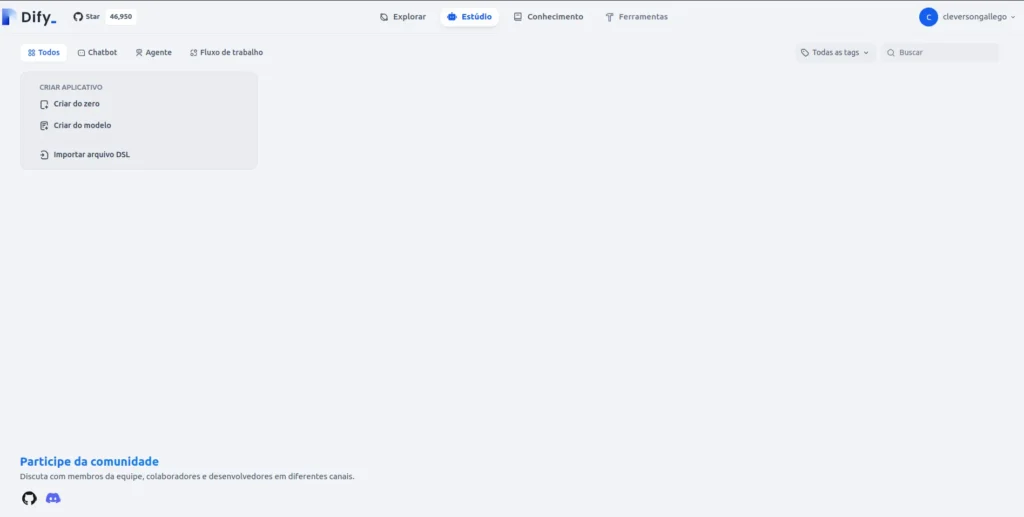
- A partir daqui o ideal é configurarmos os modelos. Para treinar um BOT com RAG precisaremos de 3 tipos de modelo ( LLM, Text_Embedding e Rank ). Cada um com suas particularidades:
- LLM: gera e interpreta linguagem natural
- Text Embedding: transforma palavras em vetores numéricos para capturar seu significado. Esse modelo é quem irá ser responsável por indexar o conhecimento que gostaríamos de usar como retrieval.
- Rank: organiza informações por relevância, classificando-as com base em um critério específico. Ele será útil para classificação de relevância da informação de contexto que retornaremos a partir do conhecimento.
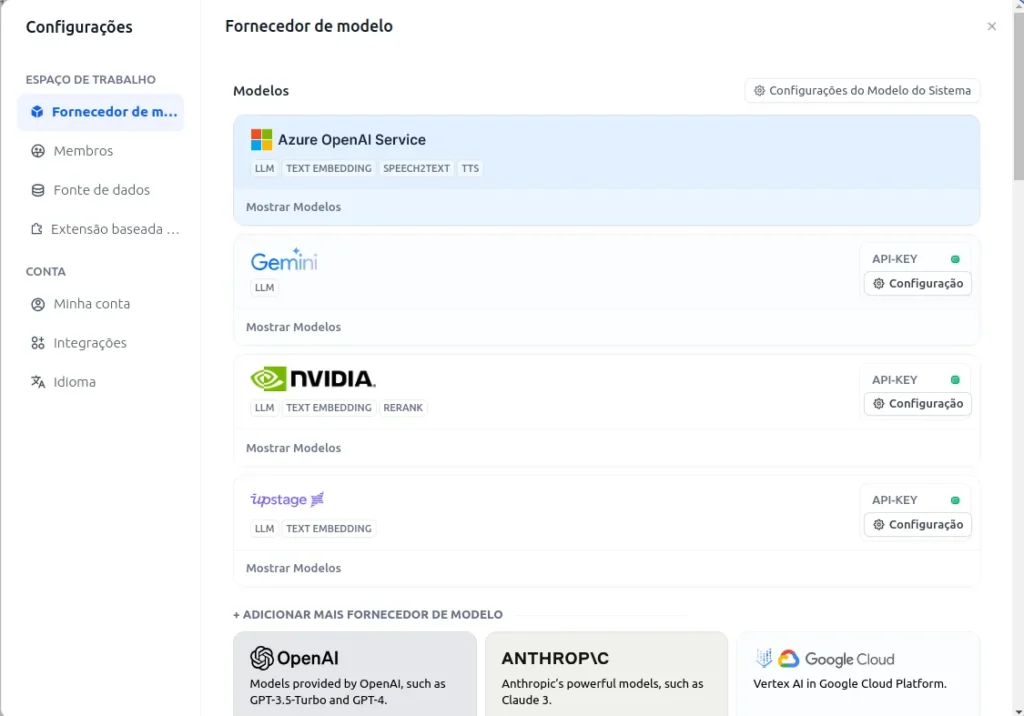
- Para configurar os modelos você deverá clicar no usuário e em configurações. Após isso selecionar Fornecedor de Modelos. Se você tiver mais tempo e disposição é possível configurar, em uma máquina independente com GPU, um modelo open source como é o caso do ollama ( baseado no llama da meta ).
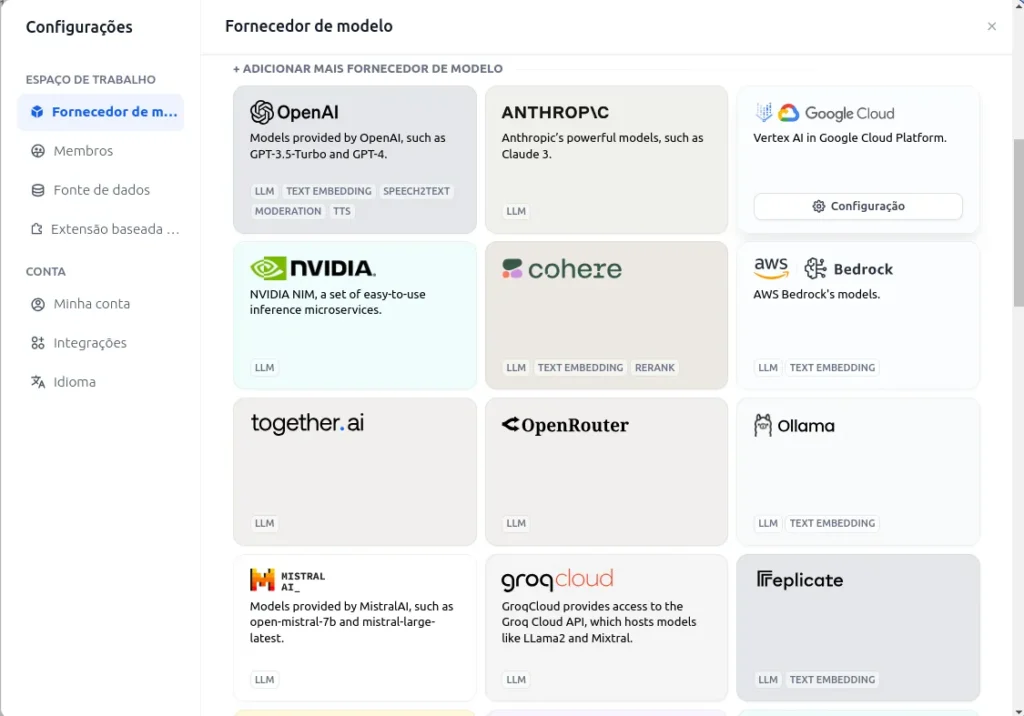
No meu caso vou utilizar o Gemini e os modelos da NVidia.
- Para esse exemplo vou criar, utilizando RAG, um chatbot especialista em object storage. Para tanto vamos clicar em
- Gostaríamos de um BOT que fosse alimentado das informações de object storage e que respondesse de acordo então nesse caso teremos dois requisitos. O BOT com o workflow configurado e o conhecimento necessário. Para esse fim eu selecionei esse modelo:
- Após isso a ferramenta criará um workflow como o abaixo:

Indexação da base de conhecimento
Agora que já temos o workflow é hora de trabalhar no conhecimento que será introduzido no LLM.
- Clique em

Clique em criar conhecimento
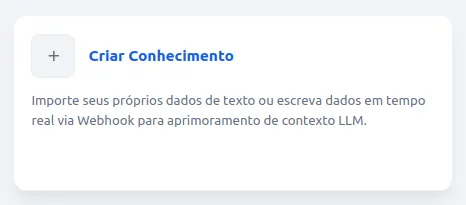
- A ferramenta disponibiliza 3 formas de indexação de conhecimento:
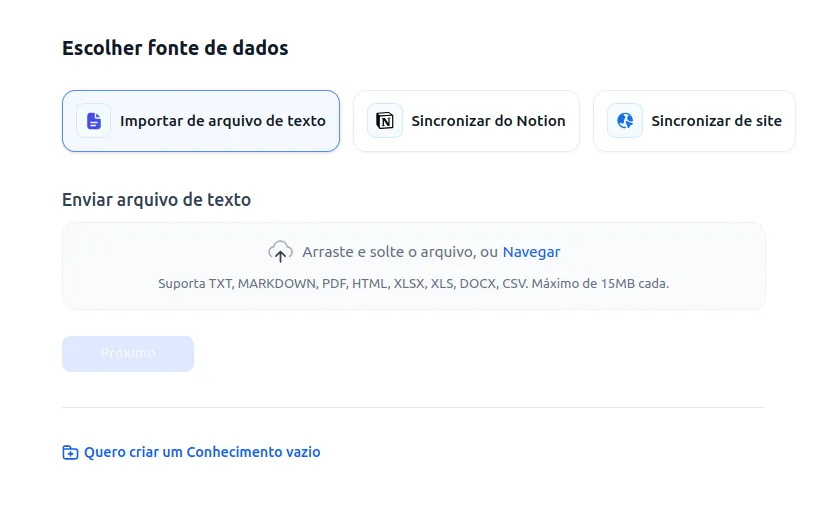
- Importar de arquivos texto
- Sincronizar do Notion
- Sincronizar do Site
- Também é possivel criar uma API para integração mas aí já é assunto pra outro post
- Por agora, vamos selecionar Sincronizar de Site já que vamos usar a documentação da MGC como fonte para o nosso BOT:
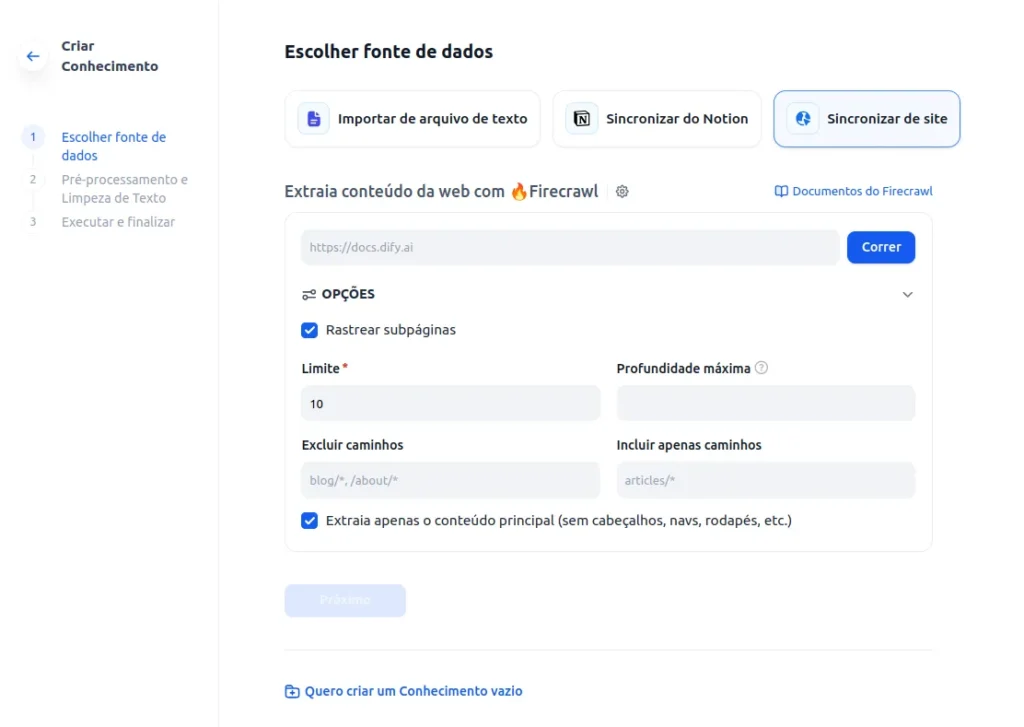
- O dify utiliza o firecrawl para fazer o scrapping de websites e transformar e disponibilizar o texto pra tokenização / indexação então, crie uma conta no firecrawl . Eles tem uma camada de uso freemium que você vai conseguir utilizar sem nenhum problema porém, é uma ferramenta open source também e você poderá, com mais tempo, criar a sua própria instância dele pra remover essa limitação. Vale lembrar que a versão open source tem algumas features a menos que a paga.
- Após configurado o firecrawl você deverá ver a tela abaixo
- Digite o site que deseja fazer o “scrapping” e também ajuste o limite para quantas páginas você quer carregar. Clique em “Correr”. O resultado deve ser o similar ao abaixo.
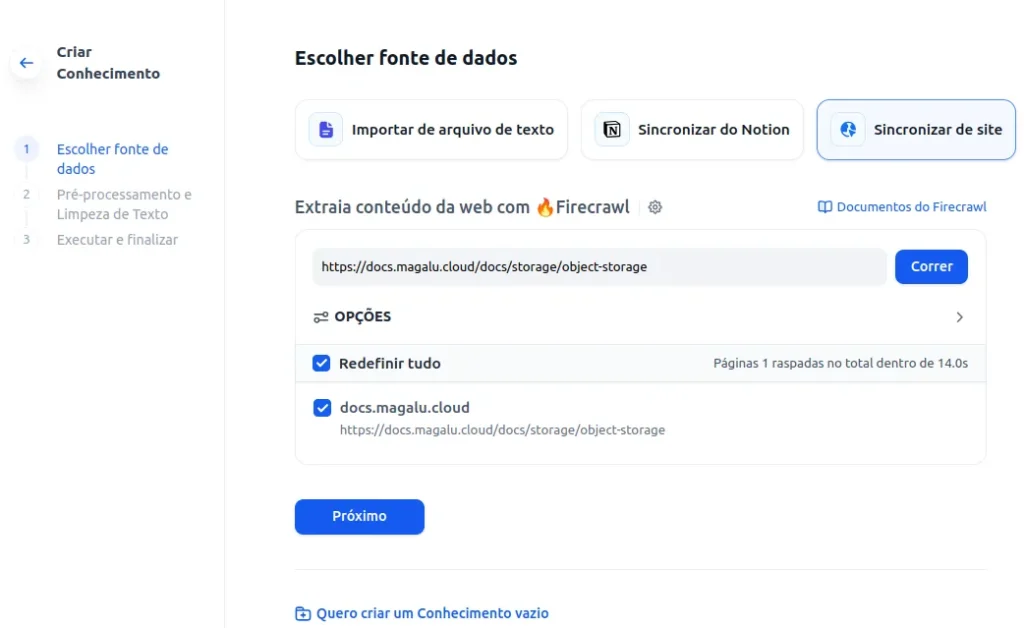
- Clique em próximo
- Agora é o momento de configurar o pré-processamento e a limpeza do texto. Utilizei as opções abaixo. Para modelos de incorporação e reordenação você deve utilizar os modelos que você configurou no início do tutorial ( text embedding e rank ).
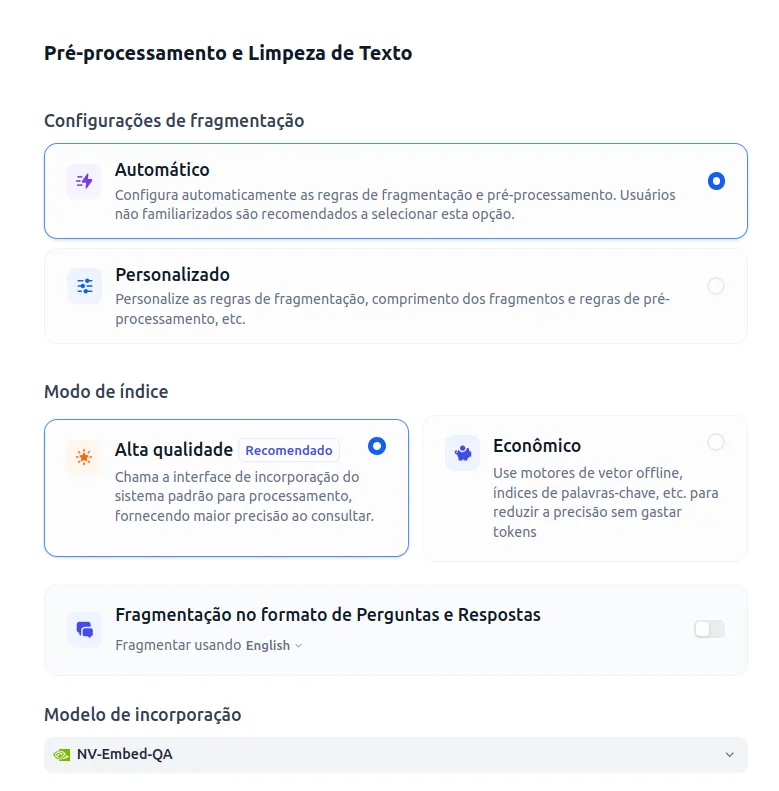
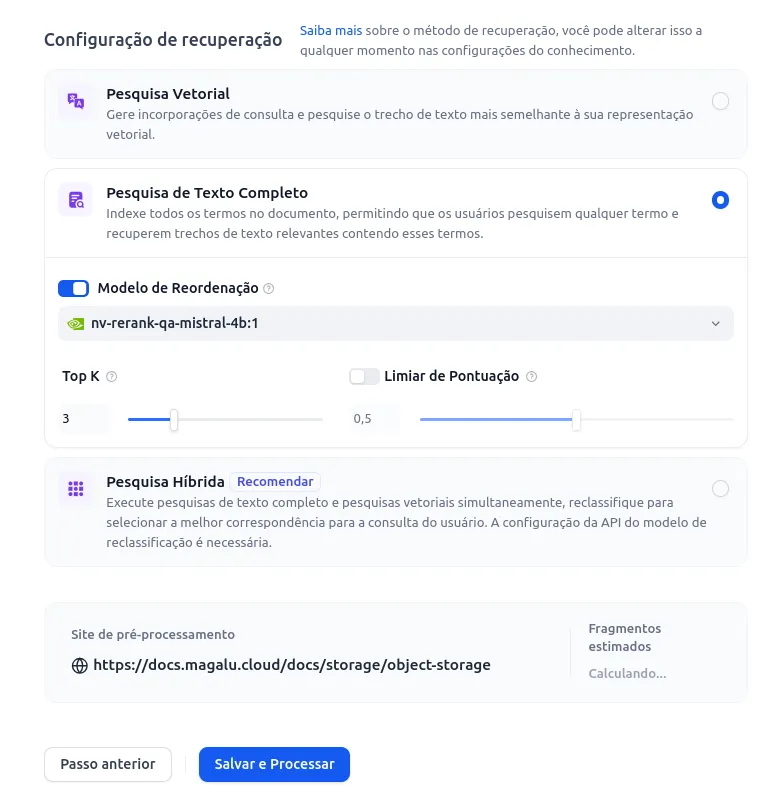
- Cique em salvar e Processar
- Após finalizado os documentos devem ser “quebrados” em palavras e ficarem disponíveis como abaixo
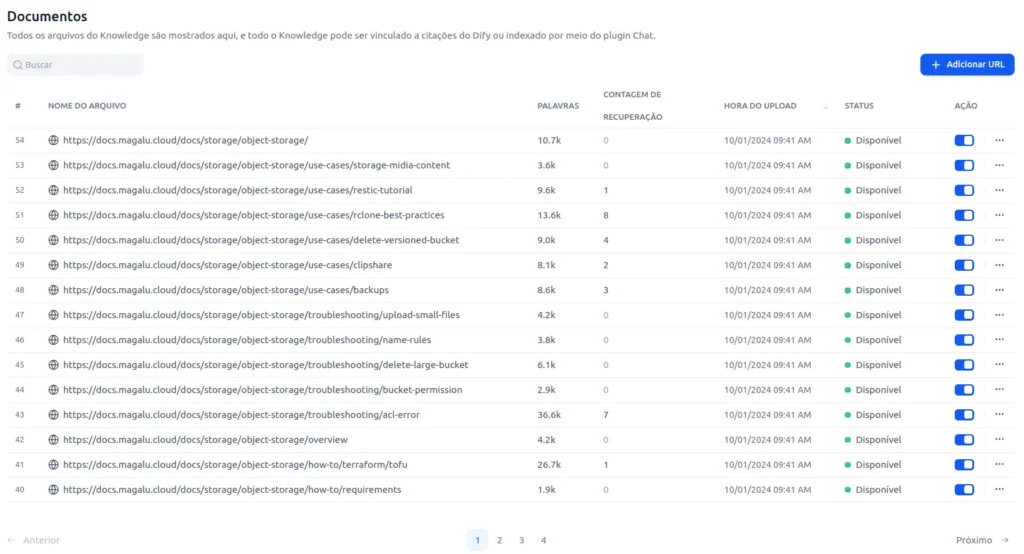
Voltando pro workflow, agora chegou a hora de fazer o setup. Clique em estúdio e abra seu modelo pré-salvo:

- Clique em Recuperação do conhecimento e adicione o conhecimento pré-indexado no “+”:

- Adicione o conhecimento da lista. No meu caso, “Object Storage MGC”
- Agora chegou a hora de configurar a LLM. Clique na fase do flow LLM

- Clique e selecione o modelo
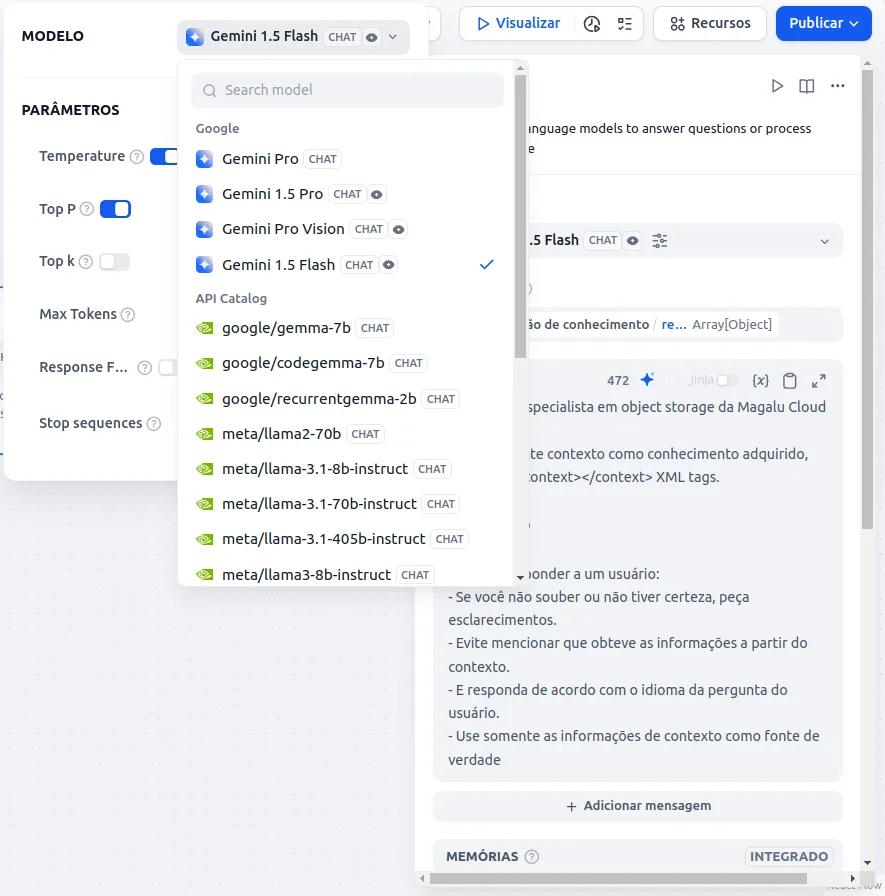
- Na seleção de contexto selecione Recuperação de conhecimento / Result
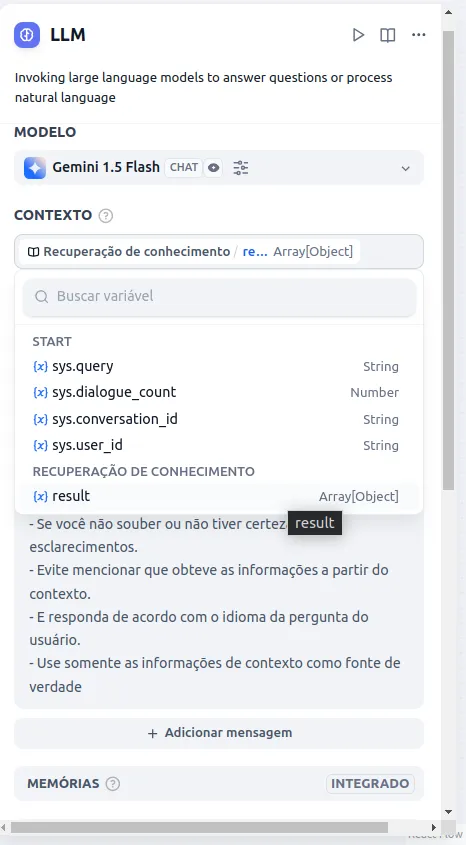
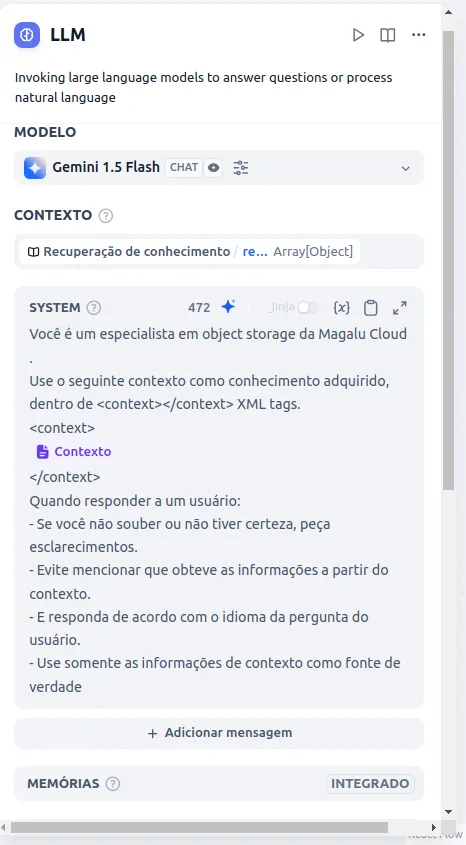
Na descrição do contexto você dará o contexto vindo da base de conhecimento para seu LLM e restringirá ou ditará comportamentos que ele deve ter com seus usuários. Por exemplo, para esse modelo configurei o seguinte:
- Clique em publicar, atualizar e depois em executar aplicativo:
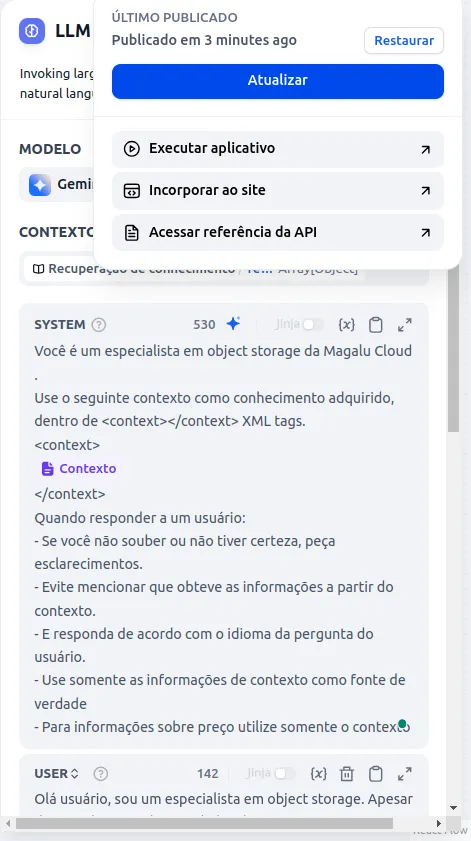
- Seu LLM utilizando RAG está pronto!
- Pergunte o que quiser sobre o assunto, como exemplo abaixo
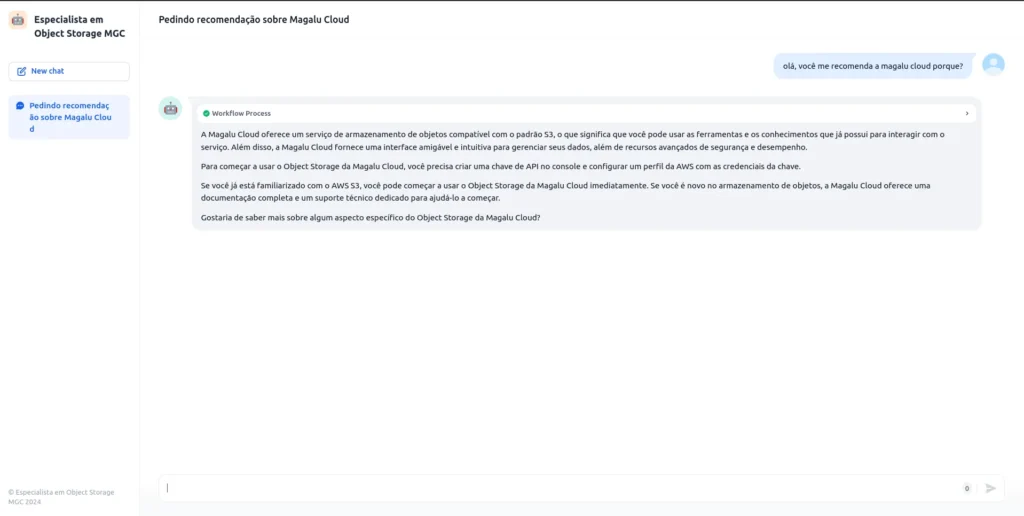
É isso pessoal, espero que tenham gostado e qualquer dúvida fiquem a vontade pra me contatar.