
Minimum requirements to execute the tutorial:
- An account on Magalu Cloud with public preview enabled
- Linux Knowledge
- Docker containers Knowledge
- GitHub Knowledge
- A computer, of course, running any operating system with internet access
As the Product Manager for the Object Storage and Block Storage products on Magalu Cloud, I’m proud to be part of building the first Brazilian cloud. With documentation and support in Portuguese, and regions in Brazil—finally, a cloud we can call our own!
Recently, we launched our public preview where we made Virtual Machines and Block Storage available to the market, in addition to having launched Object Storage at the beginning of April. So, I thought, why not build a cool AI solution using these three tools? Well then, let’s go!!!
What is RAG?
In the universe of NLP (Natural Language Processing), the advent of LLMs (Large Language Models) has been and continues to be a revolution in the modern world. In this environment, RAG (Retrieval-Augmented Generation) stands out.
RAG is a technique that combines searching for information from external sources (retrieval) with text generation by AI models, such as GPT, to create more accurate and contextualized responses. In other words, imagine having a model like ChatGPT, tailored to a specific subject, and able to use that context to act as a “specialist” in the topic. Well, this technique is called RAG.
AI Case Study – on Magalu Cloud
While chatting with our dear Leonardo Claudio de Paula e Silva (Chapter Lead – Machine Learning) here at Luiza Labs, I got an excellent recommendation: the open-source tool dify . It’s a tool for developing LLMs and orchestrating AI agent workflow applications using an RAG engine. And all of this comes with a clean, modern interface and smooth usability!
Even though it’s open source, the tool offers a range of pricing options (for hosting with them) and a free sandbox for up to 200 messages. This means messages for the available models, including several pre-configured ones like Anthropic, Llama2, Azure OpenAI, Hugging Face, etc.
Since our goal is to do this on MGC (Magalu Cloud), we’ll configure this tool within the cloud structure to avoid this limitation! Ready to dive in?
The Implementation
- First, go to magalu.cloud and create an account. Also, enable the Public Preview to access the Virtual Machine and Block Storage products.
- After creating your account, access the Cloud Portal. You will see a screen like this:
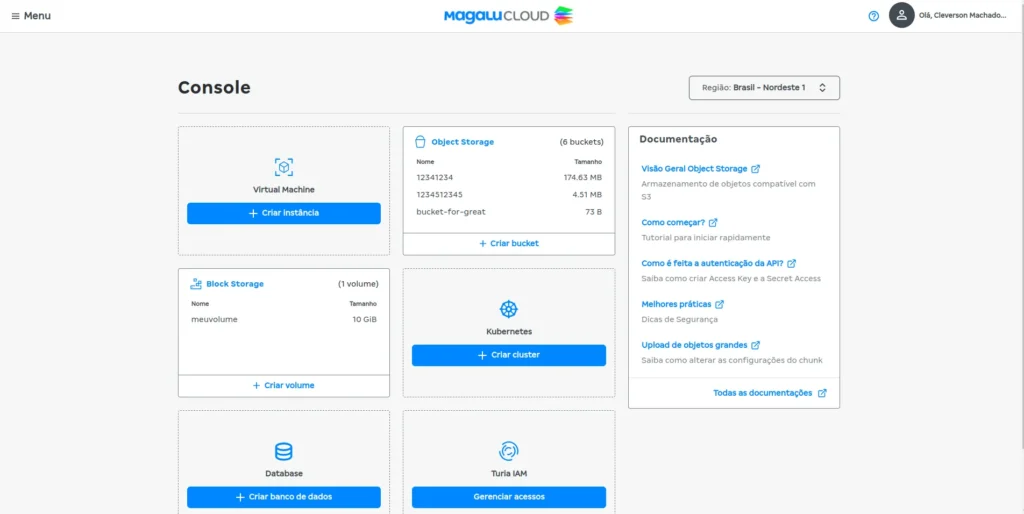
- After entering the portal, in the Virtual Machines section, click on

- On the instance creation screen, select the region (br-se1 – Southeast) and the image for your VM. In my case, I selected Ubuntu 24.04 LTS.
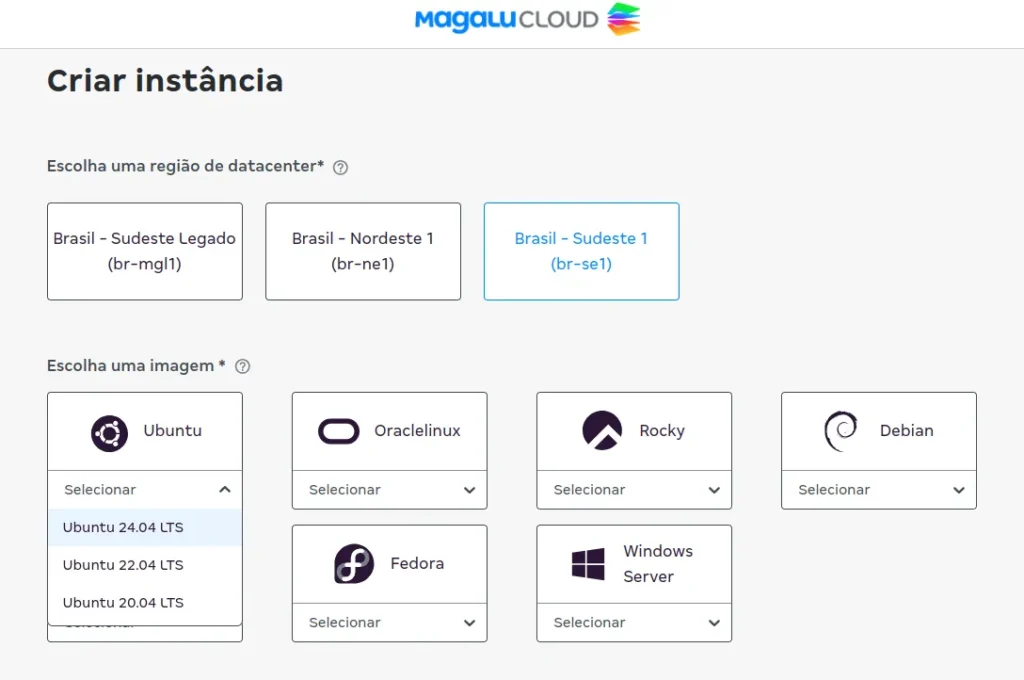
- After that, select the instance type (the recommended instance for this case, according to Dify, would be ≥ 2 CPUs and RAM ≥ 4 GB).
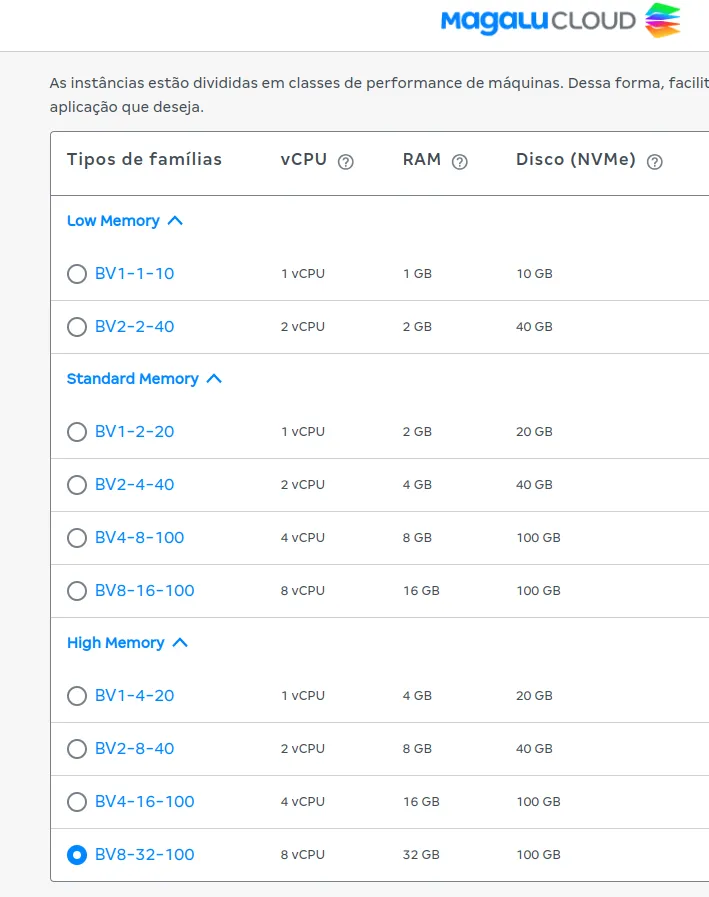
- To access the machine, we must create or insert an existing SSH key. In my case, since I am using Ubuntu as my local operating system, I just need to execute the following command in the terminal prompt:
ssh-keygen -t rsa- After that, follow the corresponding steps, and voilà. Just name your key and place the hash of the public key in the designated space. It is important to note that the key should not have line breaks. For more information on the SSH key creation procedure, consult here.
- Name the instance
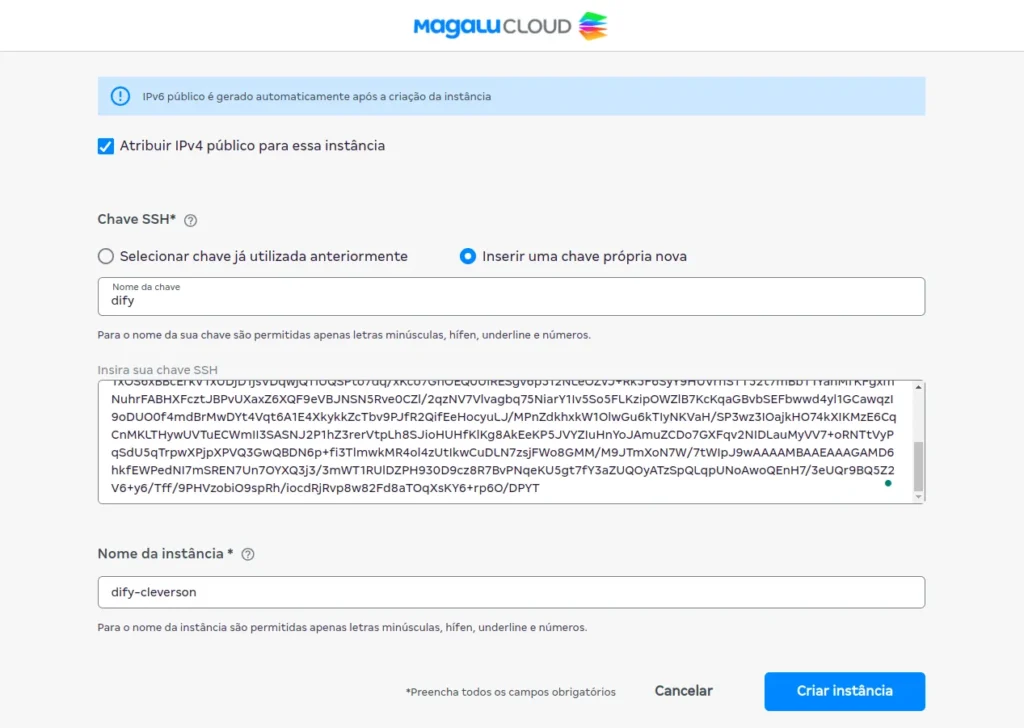
- Click on “Criar Instância”
- After your instance is created, it’s time to access it. Grab the available Public IPv4 by clicking on your VM and then clicking on “copy” as shown below:
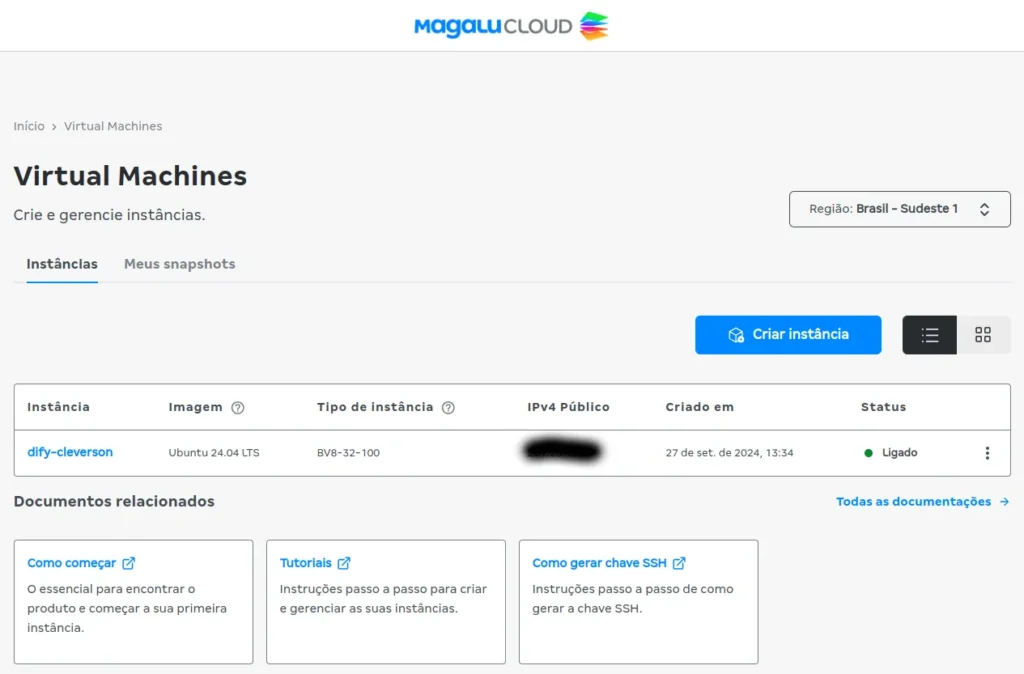
- After obtaining the public IP of your VM, simply connect via terminal using SSH. In my case, on Ubuntu, I used the command below:
ssh ubuntu@your_vm_ipUpon connecting to the machine, the idea is to execute the commands as per the manual :
- Install Docker on your machine; in my case, Ubuntu, by following the tutorial.
- Clone the repository on your VM.
git clone https://github.com/langgenius/dify.gitNavigate to the docker directory:
cd dify/docker- Copy the environment configuration file.
cp .env.example .env- Configure the MGC Object Storage as the main repository for the tool. In the MGC console, click on:

- Click on API Keys to open the API session.
- Click on
- With the ID and secret in hand, it’s time to configure the
.envfile for Docker. Configure the file according to the created secret and IDs.
nano .env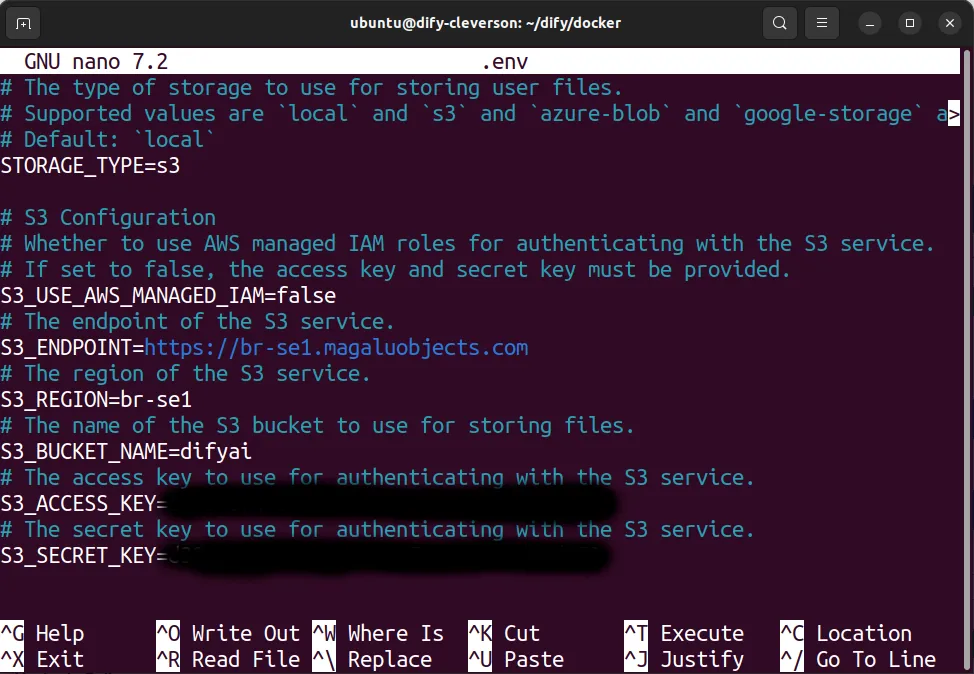
- After saving the file, let’s bring up the Docker containers.
docker compose up -dAfter executing the command, you should see output similar to this:
[+] Running 11/11
✔ Network docker_ssrf_proxy_network Created 0.1s
✔ Network docker_default Created 0.0s
✔ Container docker-redis-1 Started 2.4s
✔ Container docker-ssrf_proxy-1 Started 2.8s
✔ Container docker-sandbox-1 Started 2.7s
✔ Container docker-web-1 Started 2.7s
✔ Container docker-weaviate-1 Started 2.4s
✔ Container docker-db-1 Started 2.7s
✔ Container docker-api-1 Started 6.5s
✔ Container docker-worker-1 Started 6.4s
✔ Container docker-nginx-1 Started 7.1sFinally, check if all the containers are running properly:
docker ps -aThe output should be something similar to below:
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:0.6.13 "/bin/bash /entrypoi…" api About a minute ago Up About a minute 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db About a minute ago Up About a minute (healthy) 5432/tcp
docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx About a minute ago Up About a minute 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis About a minute ago Up About a minute (healthy) 6379/tcp
docker-sandbox-1 langgenius/dify-sandbox:0.2.1 "/main" sandbox About a minute ago Up About a minute
docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy About a minute ago Up About a minute 3128/tcp
docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate About a minute ago Up About a minute
docker-web-1 langgenius/dify-web:0.6.13 "/bin/sh ./entrypoin…" web About a minute ago Up About a minute 3000/tcp
docker-worker-1 langgenius/dify-api:0.6.13 "/bin/bash /entrypoi…" worker About a minute ago Up About a minute 5001/tcpThe Dify interface.
- After successfully deploying Dify, you will be able to access it via the browser
http://your_ip
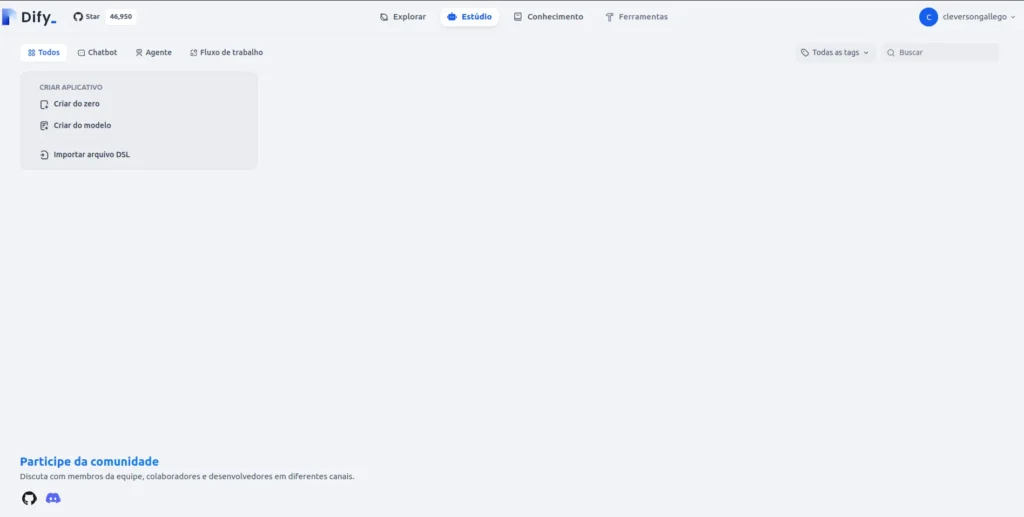
From here, the ideal step is to configure the models. To train a BOT with RAG, we will need 3 types of models (LLM, Text_Embedding, and Rank), each with its specifics:
- LLM: generates and interprets natural language.
- Text Embedding: transforms words into numerical vectors to capture their meaning. This model will be responsible for indexing the knowledge we want to use for retrieval.
- Rank: organizes information by relevance, classifying it based on a specific criterion. It will be useful for ranking the relevance of the contextual information we will return from the knowledge.
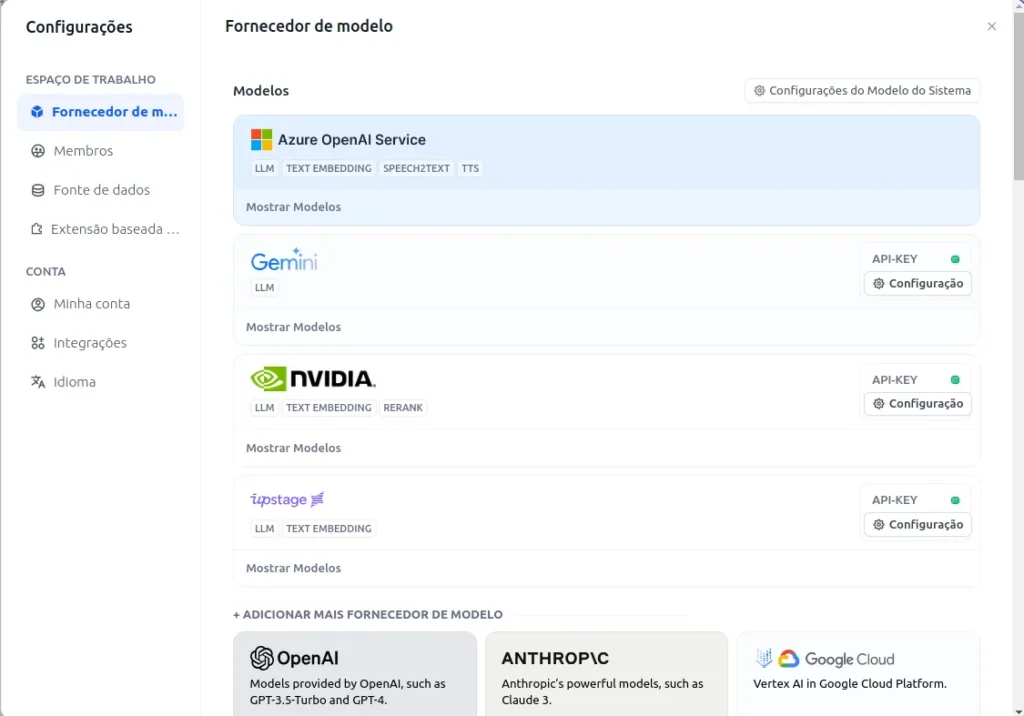
To configure the models, you should click on the user icon and then on settings. After that, select Model Provider. If you have more time and resources, it is possible to configure an open-source model on an independent machine with a GPU, such as the one found here (based on Meta’s LLaMA).
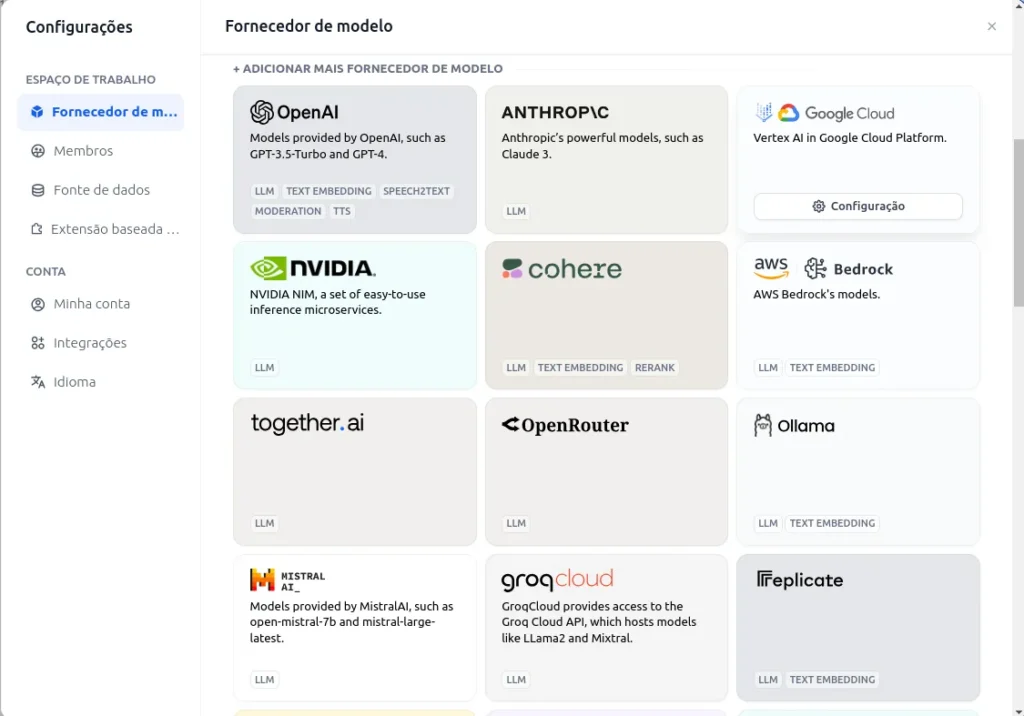
In my case, I will use Gemini and NVIDIA models.
- For this example, I will create a chatbot specialized in object storage using RAG. To do this, let’s click on
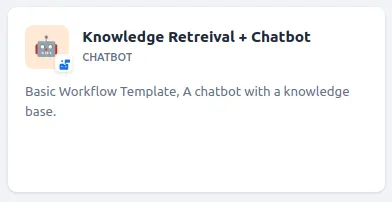
- We would like a BOT that is fed with information about object storage and responds accordingly. In this case, we will have two requirements: the BOT with the configured workflow and the necessary knowledge. For this purpose, I selected this model:
- After that, the tool will create a workflow like the one below:

Knowledge Base Indexing
Now that we have the workflow, it’s time to work on the knowledge that will be introduced into the LLM.
- Click on

- Click on “Criar Conhecimento”
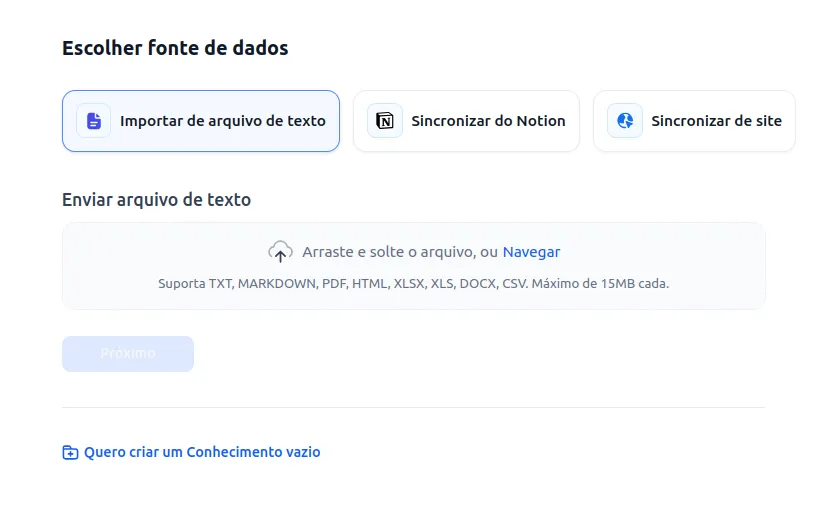
The tool provides 3 methods for knowledge indexing:
- Import from text files
- Sync from Notion
- Sync from a website
- It is also possible to create an API for integration, but that will be a topic for another post.
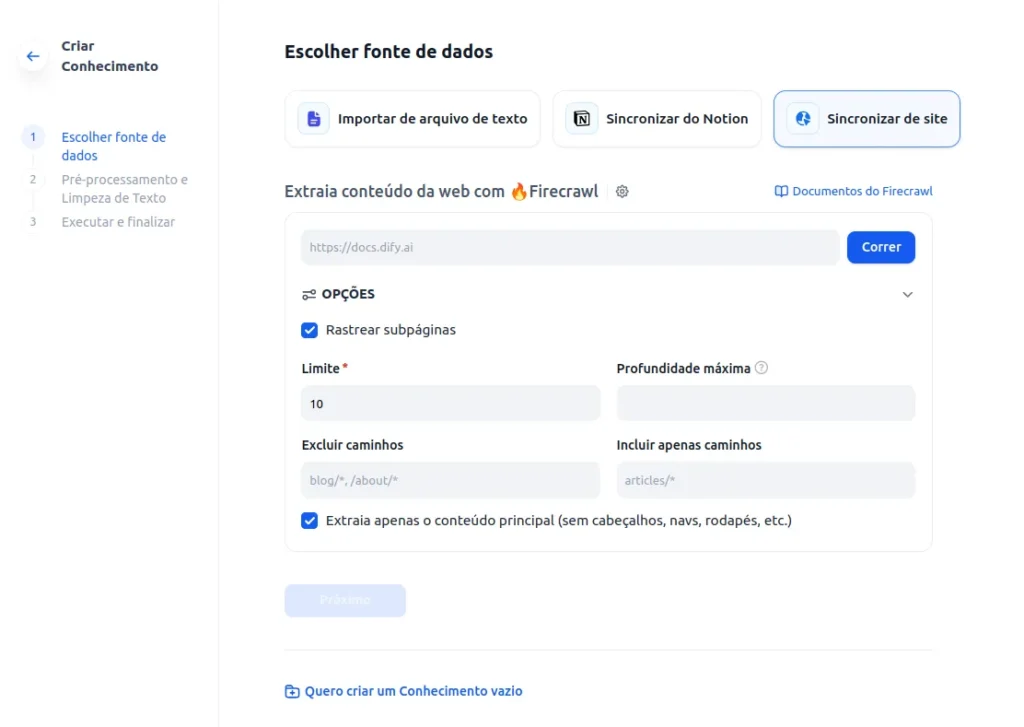
- For now, let’s select Sync from Website since we will use the MGC documentation as the source for our BOT:
- Dify uses Firecrawl to scrape websites and transform the text for tokenization/indexing, so create an account on Firecrawl. They have a freemium usage tier that you can use without any issues; however, it is also an open-source tool, and with more time, you can create your own instance to remove this limitation. Keep in mind that the open-source version has fewer features than the paid one.
- After configuring Firecrawl, you should see the screen below:
- Enter the website you want to scrape and also adjust the limit for how many pages you want to load. Click on “Run.” The result should be similar to the one below.
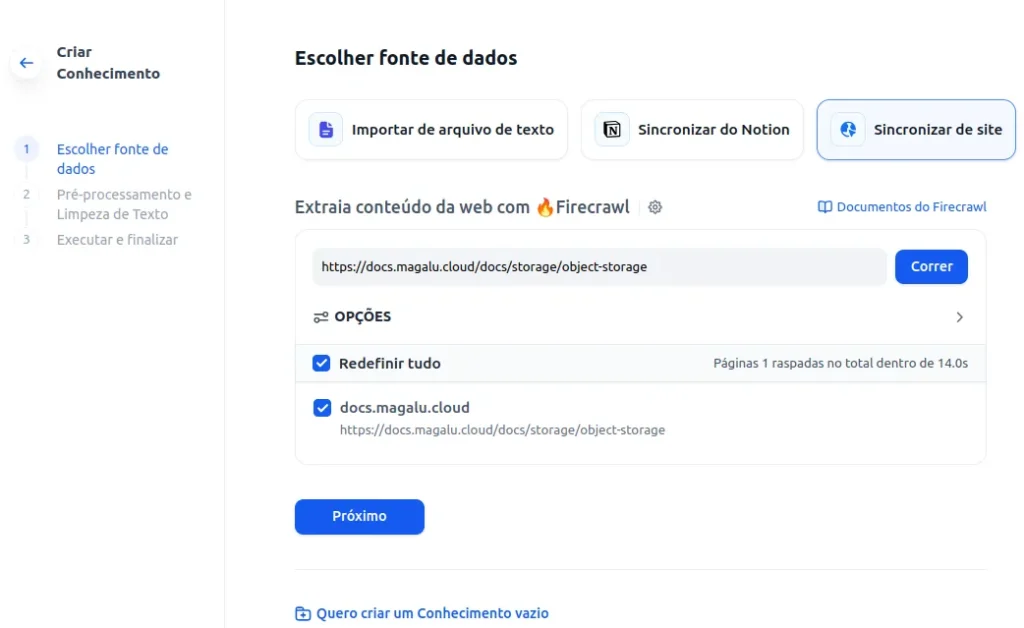
- Click on Next.
- Now is the time to configure the preprocessing and cleaning of the text. I used the options below. For embedding and ranking models, you should use the models you configured at the beginning of the tutorial (text embedding and rank).
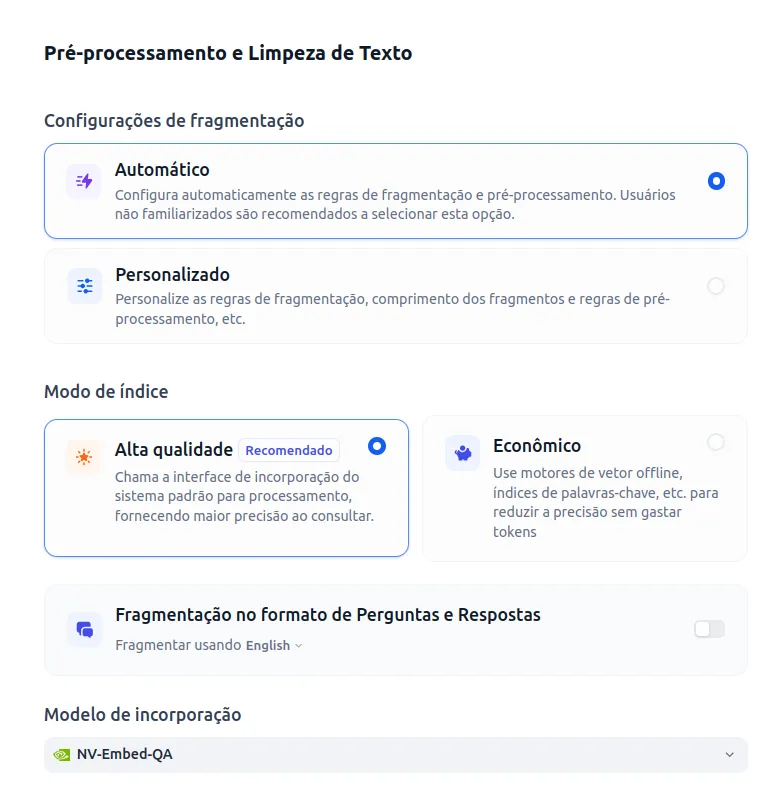
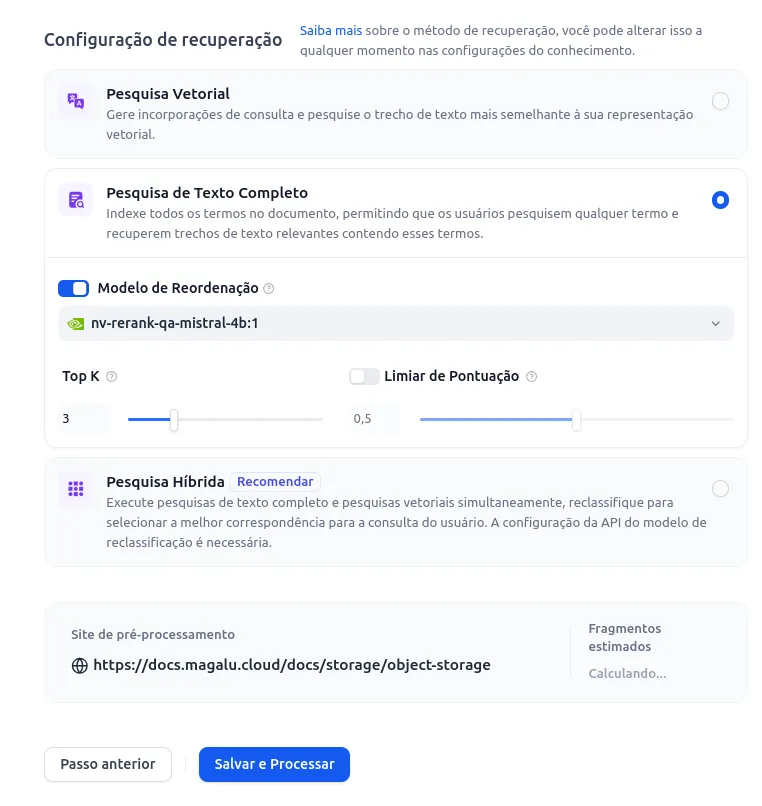
- Click on Save and Process.
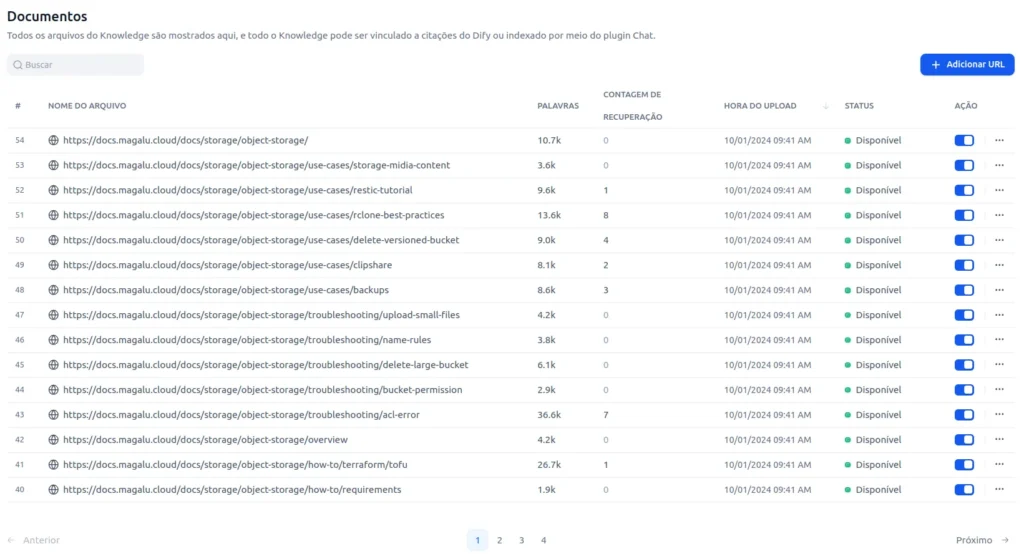
- Once finished, the documents should be “broken down” into words and available as shown below:
- Returning to the workflow, now it’s time to set it up. Click on Studio and open your pre-saved model:

- Click on Knowledge Retrieval and add the pre-indexed knowledge by clicking on the “+”

- Add the knowledge from the list. In my case, “Object Storage MGC.”
- Now it’s time to configure the LLM. Click on the LLM phase of the flow.

- Click and select the model.
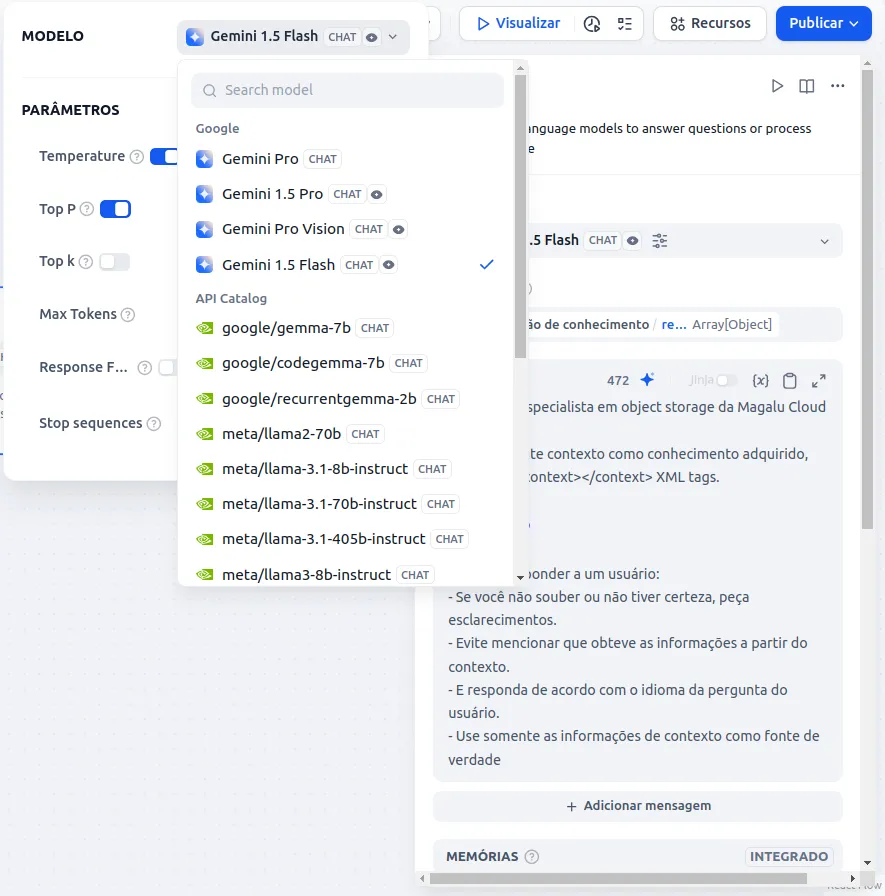
- In the context selection, choose Knowledge Retrieval / Result.
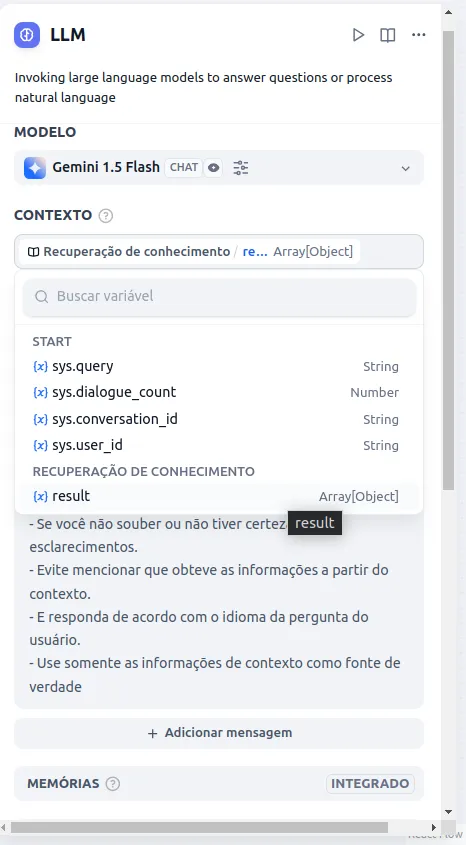
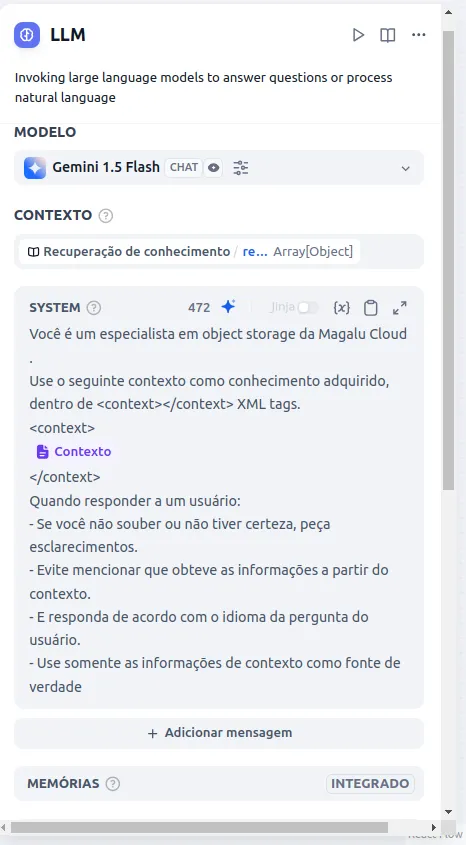
- In the context description, you will provide the context from the knowledge base for your LLM and restrict or dictate behaviors it should have with users. For example, for this model, I configured the following:
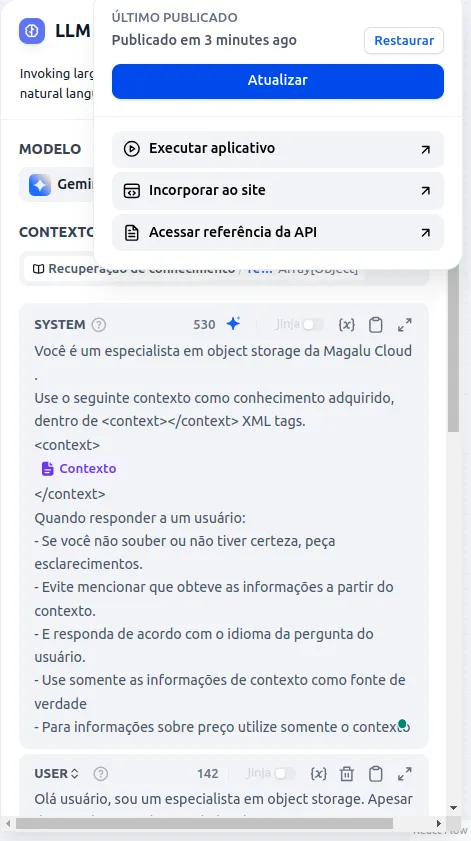
- Click on Publish, then Update, and finally Run Application.
- Your LLM using RAG is ready!
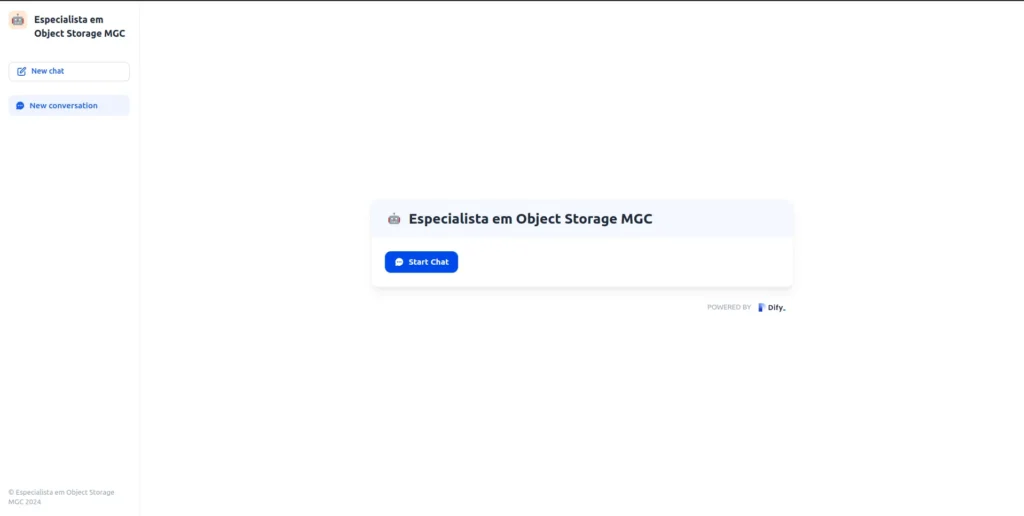
- Feel free to ask anything about the topic, like the example below:
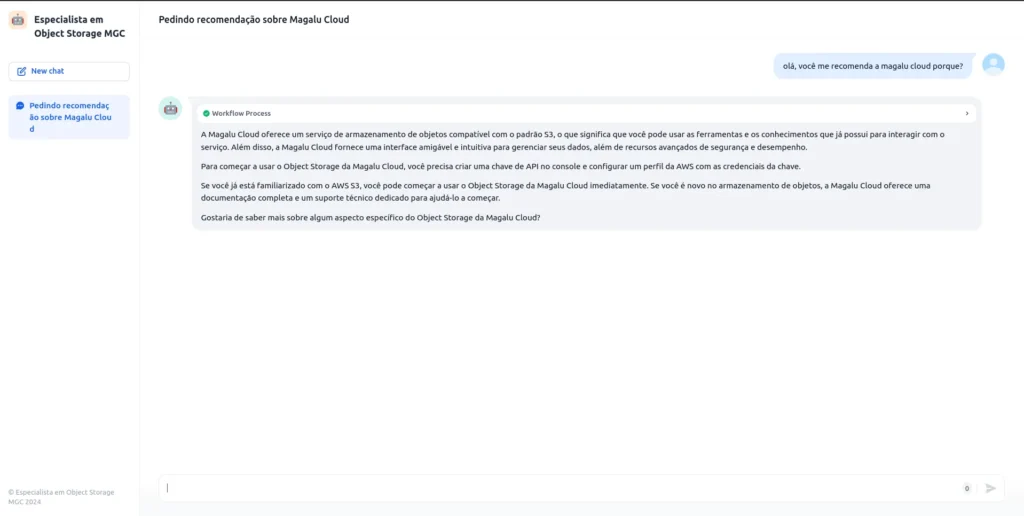
That’s it, everyone! I hope you enjoyed it, and if you have any questions, feel free to reach out to me.